Compressed Representation: A Really Good Idea
Compressed representation is a really good idea. In a nutshell, the idea is this: “There are lots of words. Lots of words mean the same thing. Lots of times the same word means different things. It would be nice if we only had one word per concept. Let’s make a neural network figure that out.” Voilá!
My machine learning toolbox Aij is open source and available on Github. I’ll be using the NeuralNetwork class and the BackpropTrainer to walk you through a rudimentary implementation. What we want in the end is to have a word vector map into a denser semantic vector. If that doesn’t make sense, fear not. We will explain shortly. If you already understand semantic vectors and just want to see the implementation details, skip down to the sign.
This document does assume that you have some understanding of programming and a remote familiarity with machine learning.
When you’re searching on the internet, be it Google, Bing, or DuckDuckGo, the search engine needs a way of mapping from each word in your query to a result. The naïve approach would be to take the search query, split it on the word boundary, and go iterating through each word of each document, counting the number of times the words overlap. This was, for a short while, the approach that some search providers used. (Recall, if you can, the era before Google.)
There are some problems with this method: first, you get LOTs of spurious results when a term happens over and over again in a document. Second, long documents get an unfair advantage over shorter ones, even though the shorter ones might be more relevant. Third, performance isn’t great since you need full-text in memory. I could go on.
You can see some improvements by going from checking for each word into a matrix representation. If you have instead table with a page name and a big vector of all the words in a document, you speed up your search tremendously because you can do a simple dot product between your search vector and your document vector.
Perhaps we’re getting ahead of ourselves. Let’s start by defining a ‘dictionary’. A dictionary is a big map which goes from a word to a number. Here’s my dictionary:
the -> 0 cat -> 1 dog -> 2 my -> 3 ran -> 4
I can use a dictionary to produce a word vector or sentence vector. A vector is an array of length ‘# of words’. If I’ve seen a billion different words, 20,000 of which are unique, my vector is going to have 20000 elements. In the case above, I’ve only seen five words.
The sentence vector for “My cat ran.” would be this:
"My cat ran" -> [the, cat, dog, my, ran] -> [0, 1, 0, 1, 1]
Note that each word in the sentence becomes a ‘1’ in the sentence vector. The position of the ‘1’ is determined by the dictionary.
Let’s really quickly review what ‘dot product’ is. Mathematically, a dot product is the sum of the products of the respective elements.
“What?”
Let’s look at the dot product of two vectors, <2, 3, 0> and <1, 4, 5>.
“The respective elements…”
2, 1 and 3, 4 and 0, 5.
“The product of…”
2*1 = 2, 3*4 = 12, 0*5 = 0.
“The sum of…”
2+12+0 = 14.
So the dot product takes each corresponding pair of items in each vector, multiplies them, and adds the result.
If we want to say how similar our document, “My cat ran.” and the page “My dog ran.” are, we can look at the dot product of these two vectors!
[0, 1, 0, 1, 1] (dot) [0, 0, 1, 1, 1] = sum(0*0, 1*0, 0*1, 1*1, 1*1) = 2
So, “My cat ran” and “My dog ran” have a match of two. Compare this to the similarity of “My cat ran” and “The dog ran”.
[0, 1, 0, 1, 1] (dot) [1, 0, 1, 0, 1] = sum(0*1, 1*0, 0*1, 1*0, 1*1) = 1
A similarity of just 1!
Dot product is fast to compute and can be done in parallel for a lot of pages at the same time. Still, there are some problems. You’ll note that the vectors are _really_ sparse. That is, most of the 20k rows are zeros. That’s not a problem in and of itself, but it also means when words change form (like ‘ran’ to ‘run’), we might miss an entry for them. It would be handy if we had only ONE word for each CONCEPT. So instead of one entry for ‘feline’, ‘cat’, ‘gato’, ‘neko’. It would be some ‘high-dimensional’ concept in a ‘feature space’. Our objective is to find that representation.
Skip here if you only care about implementation.
We want a ‘compressed’ representation of the words, and we don’t want to hand-craft that representation. What we can do is have our network make this representation. We can take a neural network and give it a bunch of input nodes and THE SAME NUMBER OF OUTPUT NODES. The number of hidden nodes will determine the size of our ‘semantic vectors’. We then train the network using our input vectors as both the examples and the labels! The network has to find a way to encode (using the hidden layers) a compressed representation that best holds the information from the input layers. Here’s what that might look like:
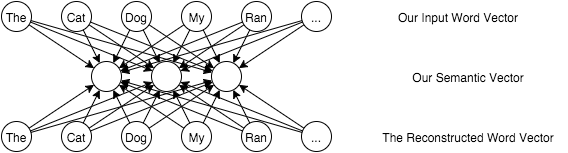
To train this network, all we have to do is make a bunch of sentence vectors and push them through a neural network! It’s that simple! (Okay, maybe not, but it’s a good short summary.) If we can train an autoencoder on a bunch of sentences, hopefully ‘semantically similar’ terms will have vectors which are closer to each other. As an example, dog and cat are probable semantically closer than dog and computer. Here’s the output from one of the unit tests in my library:
Words array: [i, have, a, cat, and, a, dog, i, own, a, computer, my, cat, chases, ...] Sentences array: [i have a cat and a dog, i own a computer, my cat chases my dog, ...] cat vec: [0.228247, 0.096414, 0.127684, 0.234154, 0.378221] dog vec: [0.349040, 0.114843, 0.116345, 0.309349, 0.140704] comp vec: [0.123077, 0.117904, 0.258514, 0.558843, -0.050910] catDog dist: 0.07712784882514626 dogComp dist: 0.17024387054490916
Note that indeed, cat and dog are more similar based on their use in the example sentences than dog and cat. Next, I’ll run through the implementation start to finish.
Let us begin by defining our training data, deciding on a ‘window’ size, and picking a semantic vector size.
We could train on all the words in a sentence at the same time, which would make this implementation very close to Principal Component Analysis. Instead, we select a window size of five words. (Which means we grab bunches of five words as we read through a sentence.)
We also select a semantic vector size of five. A bigger semantic vector size gives up more nuance with words, but requires more training data to work properly. We don’t always want more nuance.
Lastly, I’m hard-coding the training data because I am lazy. Lateral.io has an awesome collection of articles from Wikipedia which would work well here, but I’m just going to have one big sentence separated by newlines.
I start by breaking the training data into words and sentences. The words are used first to build the dictionary.
final int WINDOW_SIZE = 5;
final int HIDDEN_LAYER_SIZE = 5;
String paragraph =
"i have a cat and a dog\n" +
"i own a computer\n" +
"my cat chases my dog\n" +
"i enjoy machine learning\n" +
"my computer runs machine learning problems\n" +
"my pets are a cat and a dog\n" +
"this machine learning problem is expecting unique words\n" +
"i use github to store my machine learning code\n" +
"i hope this code will produce good results\n" +
"this test problem is fun and boring at the same time\n" +
"my cat and dog are fun\n" +
"my cat and dog are named cat and dog\n" +
"i am bad at names\n";
String[] words = paragraph.split("\\s");
String[] sentences = paragraph.split("\\n");
I want to be able to go from a word to its index in the dictionary and back from an index to a word. The index to word part can be done with just an array of strings. Easy peasy. The word to index I do with a Map.
// We have to be able to map from words to our semantic vector.
// Build a mapping without stemming or chunking.
List indexToWord = new ArrayList<>();
Map wordToIndex = new HashMap<>();
for(String w : words) {
// Expensive unique lookup, but this is just a test.
// If the word is in the list already, don't bother.
int foundAt = -1;
for(int i=0; i < indexToWord.size() && foundAt == -1; i++) {
if(indexToWord.get(i).equals(w)) {
foundAt = i;
}
}
// Not in the list so far, so add it to the end and keep the index so we can find it again.
if(foundAt == -1) {
indexToWord.add(w);
wordToIndex.put(w, indexToWord.size()-1);
}
}
Be aware that I'm only adding unique words to the mapping. Now that that's finished, we've got our dictionary to make sentence vectors. It's time to go through our sentences and produce some training examples!
// Make our training examples.
int exampleIndex = 0;
Matrix examples = new Matrix(sentences.length*8, indexToWord.size(), 0.0);
for(String sentence : sentences) {
String[] sentenceWords = sentence.split("\\s");
for(int window = 0; window < sentenceWords.length-WINDOW_SIZE; window++) {
for(int j=0; j < WINDOW_SIZE; j++) {
String w = sentenceWords[window+j];
examples.set(exampleIndex, wordToIndex.get(w), 1.0);
}
exampleIndex++; // Each window of three words is an example.
}
}
If I were to run a sliding window over this sentence, it might look like this:
[If I were to run] a sliding window over this sentence, it might look like this:
If [I were to run a] sliding window over this sentence, it might look like this:
If I [were to run a sliding] window over this sentence, it might look like this:
... and so on.
So our first sentence vector has 1's for the words 'if', 'i', 'were', 'to', and 'run'. Repeat until the end of the sentence.
Now that we have our examples, it's time to set up our network. Remember, we want it to have the same number of inputs as outputs, and we want the inputs to be the size of our dictionary.
NeuralNetwork nn = new NeuralNetwork(new int[]{indexToWord.size(), HIDDEN_LAYER_SIZE, indexToWord.size()}, new String[]{"linear", "logistic", "linear"});
My choice of 'linear', 'logistic', 'linear' is somewhat arbitrary. You could use 'tanh' for all of them or any combination. A single caveat: at least ONE layer must be nonlinear. (The product of any set of linear operations is linear. We need this to be nonlinear.)
Finally, we make our trainer, tweak some variables (like how long we want it to run) and let it train.
BackpropTrainer trainer = new BackpropTrainer();
trainer.momentum = 0.0;
trainer.learningRate = 0.02;
trainer.batchSize = 10;
trainer.maxIterations = 10000;
trainer.earlyStopError = 0.0;
trainer.train(nn, examples, examples, null);
Now go make some coffee or read a book, since this will be training for a while. When it's finished, we can use our network to get the semantic-space representation of any word or words it has seen:
Matrix input = new Matrix(1, indexToWord.size());
input.set(0, wordToIndex.get("cat"), 1.0);
Matrix catActivation = nn.forwardPropagate(input)[1];
input.elementMultiply_i(0); // Reset so we can reuse this.
Just like above, we're making a vector with the same number of entries as the dictionary and setting the index of our query word to '1'. The tricky part here is that nn.forwardPropagate(input)[1] bit. Remember in the diagram above how layer 0 is our raw word vector? And layer 2 is our reconstructed vector? That means layer 1 is our semantic vector!
The elementMultiply_i(0) just resets the input vector to zero.
We can do this for whatever word pairs we like to determine how different they are! I'm using squared-error here instead of abs() or L1 error, but the same idea applies. Cosine-distance is also immensely popular because it gives a nice, normalized vector. I'm excluding it here only for the sake of brevity. Go look it up. ;) Smaller distances means the words are closer in semantic space. Think of it like peanut-butter being close to jam in the grocery store. Things which are semantically similar are closer.
Matrix catDogDiff = catActivation.subtract(dogActivation);
double catDogDistance = catDogDiff.elementMultiply(catDogDiff).sum(); // Squared distance.
Matrix dogComputerDiff = dogActivation.subtract(computerActivation);
double dogComputerDistance = dogComputerDiff.elementMultiply(dogComputerDiff).sum();
System.out.println("cat vec: " + catActivation);
System.out.println("dog vec: " + dogActivation);
System.out.println("comp vec: " + computerActivation);
System.out.println("catDog dist: " + catDogDistance);
System.out.println("dogComp dist: " + dogComputerDistance);
assertTrue(catDogDistance < dogComputerDistance);
And that gives us the output we see at the start.
Semantic representations are an awesomely powerful concept which can be applied at a bunch of different levels of abstraction. We're using it now for words, but there's nothing to prevent it from being used for concepts or images or any of a large number of places. Give it a go and see what you can do with it!
Notes and Corrections
Distance and Similarity are opposite sides of the same coin. If the distance between a and b is zero, the similarity between a and b is large. I prefer distance as a metric to similarity because 0 means identical and anything bigger is more dissimilar. Things can only be so identical, but they can be infinitely different. Similarity doesn't have the same property. 0 can be 'not at all similar', but then 1 may or may not be quite similar. Similarity assumes that there's a _maximum_ amount of DISSIMILARITY. That doesn't sit well with me, but there are all kinds of ways to handle it mathematically.
All code for this is available here as part of the unit test for my library.
The article originally misrepresented this idea as 'word2vec'. Since it doesn't include the skip-gram modelling portion I am renaming it 'compressed representation'. A huge thank you to Reddit user Powlerbare for the correction!
You can read more on the following pages: